朱朝东研究组等NSR合作刊文,提出为未来分类学工作建立技术知识库的六个步骤
物种是我们用来研究、理解和保护自然世界的主要单元。因此,我们如何定义物种会对各个领域产生连锁影响,远远超出生物学的范畴。尽管如此重要,关于物种概念的争论仍持续至今,并对我们认识、研究和保护的生物产生了影响。鉴于地球上丰富生命,实现一个普遍接受的物种概念似乎是不可能的。如果分类学家等待一个普遍接受的概念,推迟他们描述和界定物种的工作,我们就有可能面临物种被命名之前灭绝的风险。
万幸的是几个世纪以来,分类学家一直在描述物种。因此,普遍接受的物种定义显然不是分类学研究的先决条件。这反映在De Queiroz(2007)的统一物种概念中:该概念将物种一词的概念基础与界定它们的操作方法分开。因此,分类学家可以在很大程度上摆脱“物种”这个令人生畏的哲学基础,但有必要形成标准化的界定方法,优化我们的操作基础和提高透明度,进而我们可以清晰地交流并使其能够有效识别物种。资金、未发布的数据等,往往会阻止多种数据类型使用,即使它们在一起使用时对鉴定得更准确(可能是自动化的)。为了进一步标准化工作,跨分类法和特定的生物类别,我们需要可比的数据和方法学。
为了真正最大化多样化数据源的价值,我们必须尽一切努力将标本与分类学家定义的正式物种名称联系起来,并统一生物学研究,而不是严格的操作单位。否则,我们将面临重起炉灶的风险,再建立一个平行的此类单位系统。这与自然保护联盟(IUCN)和濒危物种国际贸易公约(CITES)等组织数百年来的研究和保护工作基本脱节,这些组织通常使用物种名称合法运行。
权威物种名录、图像数据库(尤其是模式标本)和DNA参考库是这一谜题的关键。因此,标本应尽可能用于1)分子数据、2)形态学数据(图像等)和性状、3)地理信息和4)鉴定人历史。没有这些,我们无法确定已知物种与未知物种之间的区别,也无法有效地建立和分享我们对所描述物种的知识。此外,为了可靠地界定物种并评估其保护状况,我们必须充分考虑变异。每个物种的单次采集,仍然不足以达成许多目的。为了更有效地保护一些物种最丰富的类群,需要跨领域的积极协同。
1. 凭证和标准。所有涉及标本馆藏的研究,以及DNA的交互参考组织,都必须在馆藏中最低限度地保存凭证。所得到的标本,以及历史上有价值的标本,如类型,都应该成像并公开。同样,分类学修订应包括形态学、分子和其它可用证据,包括验证或标记为有问题的公共数据,以消除错误鉴定。在类群内,应商定保存的特定组织、预期的统一测量和成像参数的标准。
2. 数据标准和交叉可操作性。新标本数据的保存应要求一个鉴定人字段,以表明分类权威,作为可靠性的衡量标准(包括如何鉴定它们,这对可复制性特别有价值)。使鉴定版本和历史可追溯,将使多个专家能够认可鉴定结果或将其标记为有问题的鉴定。同样,应强制要求提供适当规模的位置数据。当一个新序列被上传到分子库时,它应该被自动生成为GBIF上的一个特别标记的记录(通过唯一标识符追踪到现存记录和可跨平台版本;初始链接已经建立,请参见https://www.gbif.org/dna).
3. 单一数据系统。我们设想了一个统一的平台:该平台具有集成现有数据库的集中式系统,并包括其它不同的数据类型,如相关文献、保护和保护状态、应用的物种概念等(图1;2020年2月)。一些存储库已经尝试过这一点,但充其量还处于起步阶段。这一点的核心是一个统一的物种列表,如《Catalogue of Life》,但基于不同物种概念的分歧应与分类学家携手指导纳入(从《世界海洋物种名录》开始)。
4. 物种概念论证。新物种的描述必须尽可能全面,整合所有可用数据。由于这些数据可能在物种描述(例如,DNA和形态学)方面存在分歧,我们必须明确说明新物种命名的理由,以及修订和其他地方使用的证据线,包括它们是如何整合的。这将大大提高分类学的透明度和可重复性。
5. 提高了整个过程的自动化程度。通用工作流程可以通过结合公共序列数据和物种界定方法来创建,可以在线托管,就像BOLD的短DNA条形码BIN系统一样。对于许多其它数据类型,类似的公共数据系统仍然无法实现。潜在的新物种可以从这些数据中自动识别,从而更好地实现综合分类方法,基于不断完善的参考库,利用经验证的历史标本图像和DNA序列。
6. 未知群体的代表性序列。作为完整物种描述之前的初步步骤,可以指定“模式”序列(类似于NCBI RefSeqs)。由于单个标记可能存在问题(假基因、不完全谱系分类),因此首选多个标记。这些初步的“物种”可用于保护评估和恢复,直到获得正式的物种描述。
多数步骤都以资金为前提,但同样重要的是强化支持和更相关的职业评估,以更利于数据生成和物种描述。为了支持最近对开放数据的推动,资助机构应规定,相关分子和形态数据应以标准方法(不“在合理要求下可用”)在固定时间线上公开。美国国立卫生研究院最近提出了这一建议,应该更广泛地采用。根据职业阶段和国家的不同,随着期望的规模不断扩大,这些政策可能会对那些受到法规影响的人更加公平(2020年2月)。通过在各个领域和国家之间开展公平研究,我们可以真正优化并获得生物多样性和生物多样性研究者的协同效应和成果。
该项工作是中国科学院动物研究所、中国科学院植物研究所、中国科学院昆明植物研究所、中国农业大学、南京农业大学、首都师范大学和帝国理工学院等相关国内外专家长期研讨和合作的结果。Michael Orr博士和Douglas Chesters博士得到中国科学院PIFI项目和国家自然科学基金委的持续支持;朱朝东研究组分类学工作持续得到中国科学院动物进化与系统学重点实验室经费资助。同时,吴仲义教授、翟巍巍研究员等在文稿准备过程中给予了重要的鼓励。
文章链接: https://doi.org/10.1093/nsr/nwac284
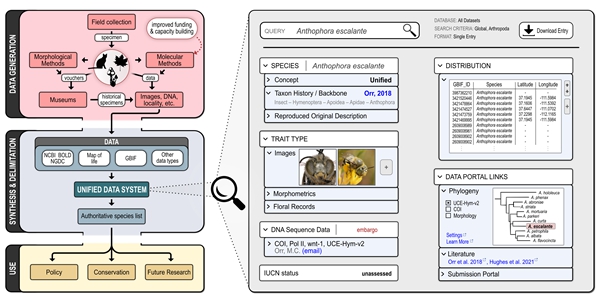
图1.协同总体样本数据的工作流。数据来源、存储位置及其后续用途。左侧给出了完整的工作流程,右侧是对统一数据系统的示例性物种级查询。
人类活动和气候变化加速生物多样性的减少,导致物种范围的转移、收缩和扩张。在全球范围内,人类活动和气候变化已对生物多样性构成了严重威胁,目前已导致全球522种灵长类动物中约68%的物种面临灭绝风险。

植物病毒素有“植物顽疾”之称,每年引起全球作物经济损失高达4000亿元。水稻作为人类重要的粮食作物之一,供给全世界一半以上的人口,主要种植于亚洲、非洲和南美洲等地区。






